同じ処理を何度も書くのか?
JavaScriptでは、同じような処理を何度も実行したい場面がよくあります。
例えば、配列の中身をすべて表示したり、一定回数同じ処理を繰り返したりする場合です。
こうした処理を、毎回同じコードをコピーして書くこともできますが、回数が増えるほどコードは長くなり、修正や管理も難しくなります。
繰り返し処理は、このような「同じ処理をまとめて実行したい」という場面で使われます。
ここでは、JavaScriptで最も基本となる for文を使い、処理を繰り返す仕組みを理解していきます。
for文
for文は、決められた回数だけ同じ処理を繰り返すための構文です。
初期値、繰り返す条件、処理ごとの更新内容を1か所にまとめて書けるため、処理の流れを把握しやすく、最も基本的な繰り返し処理として使われます。
構文
for (初期化式; 条件式; 更新処理) {
繰り返したい処理;
}
for文の構文は、繰り返しに必要な条件を順番に指定します。
初期化式では最初の状態を用意し、条件式がtrueの間だけ処理が実行されます。
処理が1回終わるごとに更新処理が実行され、再び条件式が判定されます。
なお、初期化式は更新処理の中で値が変わるため、constでは宣言できません。
コード例
//for1.js
for(let i=0; i<3; i++){
alert(i);
}
動作例
このfor文では、変数iを使って処理を繰り返しています。
順を追って何が起きているか説明します。
まず、let i = 0で変数iを用意し、最初の値として0を代入します。
これが繰り返し処理の開始位置になります。
次に、i < 3という条件式を確認し、trueの間だけ繰り返しが実行されます。
この例では、iが3未満の間、処理が続きます。
ブロック{}の中に書かれた処理は、条件に合っている間、何度も実行されます。
ここでは、現在のiの値をalertで表示しています。
処理が1回終わると、i++が実行され、iの値が1増えます。
その後、再び条件を確認し、trueならば次の処理が行われます。
この結果、alertには0、1、2の順で値が表示され、iが3になった時点で条件式はfalseになるため、繰り返しは終了します。
処理をイメージで表します。
for文の処理の流れ
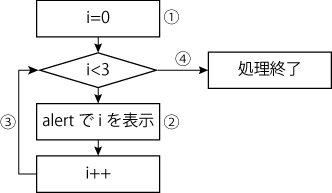
①初期化(繰り返しが始まる前に一度だけ実行)
②iの現在の値が表示されます
③iに1を加え、その後i<3の条件を確認します
④iが3になると条件式がfalseになり、処理が終了します
図とコードの説明を照合すると理解が深まるのではないでしょうか。
それではfor文の前に変数を宣言したコードを見ていきましょう。
コード例
//for2.js
let num = 0;
for(let i=0; i<10; i++){
num = num + i;
}
alert(num);
動作例
このJavaScriptの流れは大きく3つです。
まず、変数numを0で宣言します。
次に、for文のブロック内で、numの現在の値にiを順に加えていきます。
最後に、for文で繰り返し計算したnumの合計を表示します。
簡単に言うと、numの初期値0に対して0から9までの数値を順に足し合わせ、alertで合計である45を出力する流れです。
このように変数を扱うとfor文を使う意味が明確になってくるのではないでしょうか。
続いて配列を使ったfor文のコードを見ていきましょう。
コード例
//for3.js
let num = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let total = 0;
for(let i=0; i<num.length; i++){
total = total + num[i];
}
alert(total);
動作例
このコードでは、配列に入っている数値をすべて足し合わせています。
まず、numには1から10までの数値を配列として用意しています。
totalは、合計を保存するための変数として、初期値を0にしています。
for文では、iを使って配列の要素を順番に取り出します。
num.lengthを条件にしているため、配列の要素数に合わせて繰り返しが行われます。
ブロックの中では、num[i]によって現在の要素を取り出し、その値をtotalに加えています。
この処理を配列の要素数分繰り返すことで、1から10までの数値がすべて足し合わされます。
最後に、計算された合計が alert で表示されます。
変数と違い、配列で使用すると便利な点があります。
それは配列の要素数が変わっても、lengthを使っているため、同じコードで対応できる点です。
つまり、この先配列に追加・削除しても、要素数に応じて自動で処理されるため、配列の要素数を数える必要がなくなります。
ここまでfor文の基本形を扱いましたが更新処理は必ずしもインクリメントでなくてもかまいません。
それではデクリメントのコードを見ていきましょう。
コード例
//for4.js
let num = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let total = 0;
for(let i=num.length; i>0; i--){
total = total + num[i-1];
}
alert(total);
動作例
このコードは、先の記事と同じ結果が表示されます。
異なる点は、for文の初期化・条件式・更新処理の書き方です。
まず、初期化にi = num.lengthを指定しています。
これは、配列の要素数である10から処理を開始するという意味です。
次に、条件式はi > 0とし、iが0より大きい間だけ処理が実行されます。
更新処理ではi--を指定し、iを1ずつ減らしながら繰り返します。
簡単に言うと、iの初期値をnum.lengthとし、条件式をi > 0にすることで、配列を逆順に処理しています。
ブロックの中では、num[i - 1]の値をtotalに加えています。
これは、配列の要素数とインデックスの最大値が同じではないためです。
最後の要素であるnum[9]から処理するため、i - 1とする必要があります。
このようにiを1ずつ減らしながら処理しても、1から10までの数値がすべて足されるため、結果は同じになります。
なお、for文の初期化式・条件式・更新処理は、任意の式でもかまいませんが、条件式と更新処理がかみ合っていないと、無限ループや処理漏れの原因になるため注意が必要です。
例えば初期化式ならi=2でもかまいませんし、条件式はi>=10などの比較演算子を使用できます。
また、更新処理もインクリメント・デクリメントではなくi+2やi+=3などでもかまいません。
ただ、更新量が条件に対して大きい場合、処理回数もそれに応じて変化しますので、最終目的を設定することが大切になります。
では、続けて空配列を使用したfor文のコードを見ていきましょう。
コード例
//for5.js
let num = [];
for(let i=0; i<9; i++){
num[i] = (i + 1) * 7;
}
alert(num);
動作例
このコードは、九九の7の段を計算しています。
空配列numを宣言して、iが9より少ない間インクリメントを行います。
インデックスは0から始まるため、i * 7だと0×7になるため、(i + 1) * 7とします。
最後にfor文で格納された配列をalertで表示すると7の段が表示されます。
このように空配列に格納することでfor文は効果を発揮します。
for文の基本を押さえたところで、続いて配列専用のforEachを解説します。
forEach
配列を順番に処理したいだけの場合、何回繰り返すかではなく、配列の中身をすべて処理したいという目的の方が自然なことも多いでしょう。
そのような場面に特化するのがforEachです。
配列の要素を先頭から順番に取り出し、要素の数だけ処理を自動で繰り返してくれます。
構文
//基本形
配列.forEach(function(要素){
処理
});
//アロー関数
配列.forEach(変数 => {
処理
});
forEachはメソッドで、配列の要素を1つずつ取り出し、その値を関数の引数として渡しながら処理を実行します。
このとき、変数や要素には、配列の中の値が順番に入ります。
アロー関数と無名関数では書き方が異なりますが、動作はまったく同じです。
どちらの場合も、配列の要素の数だけ関数が実行され、そのたびに現在の要素を使って処理が行われます。
for文でも同じ結果を得られますが、forEachで書く方がコードがシンプルになります。
for文のコード例
//forEach1.js
const arr = ['りんご', 'みかん', 'ぶどう'];
for(let i = 0; i < arr.length; i++){
alert(arr[i]);
}
forEachのコード例
//forEach1.js
const arr = ['りんご', 'みかん', 'ぶどう'];
arr.forEach(function(products){
alert(products);
});
動作例
for文では、インデックスを使って配列の要素を1つずつ取り出しています。
そのため、初期化・条件式・更新処理、さらにlengthを意識する必要があります。
一方、forEachでは配列の要素そのものが引数として関数に渡されます。
インデックスを自分で管理する必要がなく、配列の要素に対する処理をシンプルに書くことができます。
forEachの引数名は任意で、どのような名前でも問題ありません。
後から見返してすぐ理解できるような名前をつけることをおすすめします。
続けてアロー関数に書き換えたコード例を見てみましょう。
コード例
//forEach1.js
const arr = ['りんご', 'みかん', 'ぶどう'];
arr.forEach(products => {
alert(products);
});
動作例
アロー関数に書き換えただけで、基本形と同じ結果になります。
書き方が変わっても、forEachの動作自体は変わりません。
ただし、空配列への格納を目的とする処理には、forEachはあまり向きません。
while文
for文は、初期化・条件・更新処理をまとめて書く繰り返し構文です。
while文は、それとは異なり、条件式がtrueの間だけ処理を繰り返します。
繰り返す回数が事前に分からない場合に、while文が使われます。
構文
while(条件){
処理;
}
while文は条件がtrueの間、繰り返して処理を行います。
そのため、繰り返し回数は条件次第となります。
また、条件を誤ると無限ループに陥りやすいので、条件には十分に注意する必要があります。
コード例
//while1.js
let num = 0;
let total = 0;
while (num < 10){
total += num;
num++;
}
alert(total);
動作例
while文の条件をnumの値が10より小さい場合としました。
total変数にnumを足して、その後numをインクリメントしています。
numが10になった際に条件はfalseとなるため、while文を抜けます。
alertには0~9までを足した45が表示されます。
もう一つコードを見てみましょう。
コード例
//while2.js
const arr = [3, 5, 7, 12, 9];
let i = 0;
while (arr[i] < 10) {
alert(arr[i]);
i++;
}
動作例
このwhile文は、配列の値が10未満の間だけ処理を続けます。
配列の4番目の値12で条件がfalseになるため、ここでループを抜けます。
そのため、配列の最後の9は評価されません。
条件によって終了位置が決まる処理では、while文の方が分かりやすくなります。
do~while文
do~while文はwhile文と似ていますが、少なくとも1回は必ず処理が実行されるという点が最大の特徴です。
順を追って説明します。
構文
do{
処理;
}while(条件);
doブロックの中の処理を1回実行します。
その後、条件を評価して、trueであれば再度処理し、falseなら処理終了となります。
コード例
//doWhile1.js
let num = 1;
do {
alert(num);
num++;
} while (num <= 5);
動作例
このコードでは、条件式num <= 5の間ループが実行されます。
doブロックの中でalertに現在のnumの値を表示し、インクリメントします。
numが6になった時点で条件がfalseになり、ループを抜けます。
次に、条件が最初からfalseの場合の例を見てみましょう。
コード例
//doWhile2.js
let num = 10;
do {
if (num > 5) {
alert('条件が合いません');
} else {
alert('条件が合っています');
};
} while (num < 5);
条件式はnum < 5ですが、numは10なので最初からfalseです。
しかしdoブロックの処理は 必ず1回実行 されるため、条件が合いませんと表示され、ループを抜けます。
Webでは入力チェックなどで使うこともできますが、ほとんどの場合はwhile文で十分です。
処理の継続と停止
条件分岐のswitchでは、breakを使って処理を途中で抜ける方法を学びました。
今回はループでの処理に注目し、breakとcontinueの違いを見ていきます。
breakはループ自体を終了させ、continueはその回の処理をスキップして次の回に進むという特徴があります。
どちらもループの制御に欠かせない文法なので、例を見ながら使い方を理解していきましょう。
構文
continue;
break;
continueはスキップして処理を続け、breakは処理を中止します。
ループでは場合によって非常に有効な役割を果たします。
コード例
//continueBreak.js
for(let i=0; i<10; i++){
if(i<5){
continue;
}else if(i === 7){
break;
}else {
alert(i);
}
}
このコードでは、i < 10 の間だけループが繰り返されます。
しかし、if文でiが5未満のときには continueで処理をスキップし、iが7になるとbreakでループを中止しています。
iが5以上、7未満の場合は、iの現在の値をalertで表示します。
その結果、alertは5と6だけ表示され、7になった時点でループを抜け、それ以上の処理は行われません。
このように、条件は満たしているけれど処理をさせたくない場合はcontinueを使い、条件を満たしていても処理を中止したい場合はbreakを使ってプログラムを制御できます。
無限ループ
繰り返し処理では、条件が正しくないと処理が終了しない無限ループが発生することがあります。
本来、繰り返し処理は「いつか終わる」ことを前提に書かれます。
しかし、条件式や更新処理を誤ると終了条件に到達できず、ループが終わらなくなります。
ここでは、よくある無限ループの例を見ていきましょう。
なお、動作例はブラウザが固まるため省略します。
コード例
//forError.js
for(let i = 0; i < 3; i--){
alert(i);
}
更新処理がi--になっているため、iは0,-1,-2…と減り続け、条件を満たしたままになります。
コード例
//forError.js
for(let i = 0; i < 3; ){
alert(i);
}
更新処理が書かれていないため、iはずっと0のまま。条件は常に成立し、ループが終わりません。
コード例
//whileError.js
let i = 0;
while (i < 5) {
console.log(i);
}
インクリメントを忘れたため、iは0のまま。条件が成立し続け、処理が終了しません。
//whileError.js
let num = 0;
while (num !== 5) {
console.log(num);
num -= 1;
}
条件式は正しいつもりでも、numからずっと1が引かれ続けるため5に到達せず、ループが終わりません。
このように無限ループは単純なミスで発生します。
もし無限ループに陥った場合は、ブラウザを強制終了してコードを見直しましょう。